
The data science brigade deems wrangling as essential. Ask any professional in the data science industry and they will reveal that the foremost challenge of putting data to work is getting it into a structured format. This calls for in-depth knowledge. The answer lies in the sheer complexity and diversity of datasets we encounter today. Fortune Business Insights reveals that the global data science platform market size will reach USD 133.12 billion in 2024; which is expected to grow at a CAGR of 24.7% further; to reach USD 776.86 billion by 2032. This makes understanding data a critical aspect of business management!
The vast amounts of data pool are expanding at a staggering rate. The year 2024 is expected to churn out a global data volume that is 22.5% higher than the last year (edgedelta.com). Understanding data, deducing key insights, and making stakeholders and others understand what it means takes massive skill sets. Let us take a closer look at data wrangling as a procedure, the way to go about it, and why it is so important.
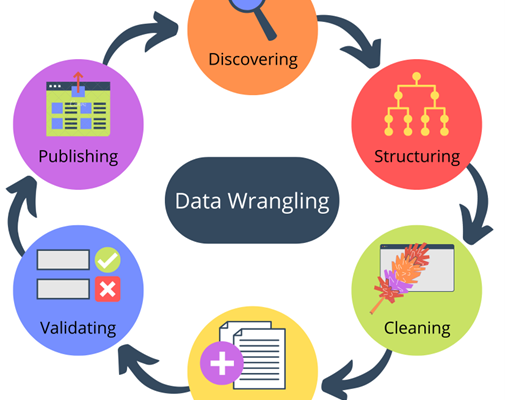
Data Wrangling:
In simple terms, data wrangling is the simple process of cleaning, structuring, and transforming raw data into a usable format for further analysis. It is also called data munging; which involves tasks such as handling missing data, or inconsistent data, formatting data types, and merging diverse datasets to prepare the data for further exploration and modeling. It makes data analysis a simpler process to delve into.
How to Wrangle Data- Step-by-Step Exploration:
STEP 1: DISCOVER
The foremost target should be to understand and explore the data thus gathered. It involves identifying data sources, data quality assessment, and gaining insights into the structure and data format.
STEP 2: STRUCTURE
Next, it is essential to organize and streamline the data thus acquired. Formatting raw data is critical to foster efficient analysis. The form of data that it will eventually take, depends on the analytical model that is being used. Data structuring broadly involves reshaping data, handling missing values, and converting data types. This brings out the most coherent and standardized data.
STEP 3: CLEAN
As the name suggests, it attends to countering inconsistencies, errors, and outliers within the dataset. Data cleaning means correcting or removing inaccurate data, handling duplicates, and addressing any anomalies that could adversely impact the credibility of the analysis.
STEP 4: ENRICH
Data enrichment is essential as boosting the database with added information reaps more context and better understanding. This could take the form of merging datasets or incorporating external data sources.
STEP 5: VALIDATE
Data validation becomes important at this stage as it ensures data quality and reliability of the entire data processing regime. It assists in building your confidence in the level of accuracy of the dataset and ensures it meets the requirements of the project.
STEP 6: PUBLISH
The final step involves publishing the data that targets documenting data lineage and the steps involved in the entire data wrangling process. Sharing metadata, and preparing the data for storage or further integration into data science and analytics tools follows soon. Data publishing fosters better collaboration and allows others to utilize data for their analysis or core decision-making processes.
Popular Data Wrangling Tools Used at Every Step:
| DISCOVERY | STRUCTURING | CLEANING | ENRICHING | VALIDATING | PUBLISHING |
| Data discovery and metadata management tools such as spreadsheets, databases, excel files, APIs, or online platforms | Data transformation tools that offer graphical user interfaces for intuitive manipulation | Machine learning-based tools that assist in outlier detection | APIs and web scraping tools to automate the retrieval of external data | Data quality tools to enforce enhanced setting and data quality standards | Data cataloging tools aid in documenting and sharing metadata; and version control tools ensure traceability of the changes made during the data wrangling process |
These data science tools for wrangling are a critical part of the entire process to make trusted data-driven decision-making possible.
Why Data Wrangling Matters- Core Benefits:
- Enriched data quality and fosters data consistency
- Increased analysis efficiency
- Supports exploratory data analysis
- Fosters data integration and adaptability
- Prepares data for machine learning and enhanced reproducibility
- Supports informed decision-making
- Reduces errors
Popular Use Cases of Data Wrangling:
- Merging datasets in marketing campaign analysis
- Handling missing values in customer relationship management databases
- Standardizing data formats for eCommerce companies for integrating product data from various suppliers
- Creating derived features from the employee performance metrics in HR analytics
However, data wrangling looks identical to data cleaning; but it should not be confused. Data wrangling and ETL (extract-transform-load) are related yet distinct processes. The difference between these critical data concepts can be facilitated by an expert senior data scientist who possesses the right mix of skill and experience earned through trusted data science certification programs. These credentials are deemed essential and weighed highly across global giants while selecting deserving candidates for the role. Build a thriving career trajectory and become invincible with the most nuanced data science tools and skillsets to make sense of the vast data pools worldwide.








